카프카 탄생 배경
최근에 MSA도 그렇고 많은 서비스들이 서로 데이터를 주고받아야 할때 위와 같은 상황이 일어난다. 소스가 어디로 데이터를 보내야 하는지가 굉장히 복잡하게 이어져있는데 데이터 복잡성이나 관리 효율적인 측면에서 굉장히 다루기 어려워지고 있었다.

이를 효율적으로 관리하기 위해서 데이터를 무조건 카프카로 보내고, Destination에서는 카프카에서 데이터를 가져오는 식으로 구성하면 다음과 같이 된다.

카프카 용어 및 설명
* 토픽과 파티션
카프카에서 메시지를 저장하는 단위 ( 파일 시스템의 폴더와 유사하다고 볼 수 있다 )
파티션은 메시지를 저장하는 물리적인 파일이며 한 개의 토픽은 한 개 이상의 파티션으로 구성된다.
그럼 어떤 파티션에 프로듀서가 값을 저장할까?
라운드로빈 혹은 키를 활용해서 파티션을 선택 - 같은 키를 활용하면 메시지의 순서를 유지시킬 수 있음을 의미한다.
컨슈머는 컨슈머 그룹에 속하고, 한 개의 파티션은 컨슈머 그룹의 하나의 컨슈머만 연결이 가능하다.
(그룹 내부의 다른 컨슈머가 하나의 파티션을 공유하지 못한다)

카프카의 성능이 좋은 이유
파티션 파일은 OS의 페이지 캐시를 사용하고, 파일 IO를 메모리에서 처리한다. 그러므로 서버에서 페이지 캐시를 카프카만 사용해야 성능에 유리하다.
Zero Copy : 디스크 버퍼에서 네트워크 버퍼로 직접 데이터를 복사한다.
컨슈머 추적을 위해서 브로커가 하는일이 단순하다. 메시지 필터링 메시지 재전송등은 프로듀서나 컨슈머가 직접 해야 한다.
묶음처리(batch)를 통해 묶어서 메시지를 전송(프로듀서), 최소 크기만큼 메시지를 모아서 조회(컨슈머).
확장에 용이한 구조를 가지고 있다. 예를들면 브로커나 파티션을 추가하거나, 컨슈머를 추가하여 처리량을 증대시킬 수 있다.
리플리카
replication factor 만큼 파티션의 복제본을 가지고 있음.
리더와 팔로워로 구성하여, 프로듀서와 컨슈머는 리더를 통해서만 메시지를 처리한다.
장애 대응 : 리더가 속한 브로커 장애가 생기면 팔로워가 리더가 됨.
프로듀서

여기서 버퍼전까지 넣어주는 Serialize, Partioner부분까지 별도의 스레드
Sender가 별도의 스레드.
이렇게 별도의 스레드로 구성하기 때문에 동시에 동작한다.
Sender는 linger.ms(전송대기시간) 설정에 따라 브로커로 메시지를 보내는데, 배치가 덜 차더라도 브로커로 바로 전송한다.
- ACK : 0, 1, ALL
Ack=0 : 빠른 전송, 카프카가 받았는지 확인하지 않는다. (0.29ms)
메시지 손실 가능성
Ack=1 : 빠른 전송, 카프카가 받았는지 체크를 한다. (1.05ms)
메시지 손실 가능성 희박하게 있음. (Ack를 받았는데, Ack를 던져주자마자 다운되면 리더가 죽고 다른 팔로워가 리더가 되는데 레플레케이션이 미쳐 되지 않아서 손실될 수 있다)
Ack = All : 느린 전송, 메시지 손실 없음 (2.05ms)
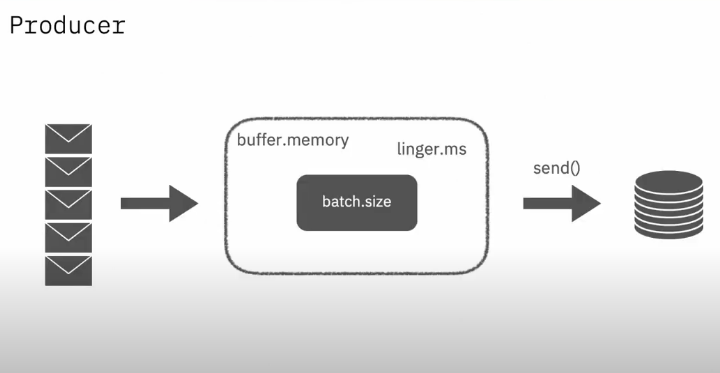
결국 buffer memory안에 메시지를 쌓고 Batch size만큼 이동하는데, linger.ms만큼 지연시간을 가지고 send하게된다.
* 기타 전송 재시도 주의 사항
중복 전송 가능, 순서 바뀜 가능 (설정값으로 컨트롤하기)
프로듀서


처음 접근이거나 커밋된 오프셋이 없는 경우
auto.offset.reset 설정을 사용한다. earliest(제일 처음 오프셋), latest(가장 마지막 오프셋), none(컨슈머 그룹에 대한 이전 커밋이 없으면 익셉션 발생)
기타 컨슈머 설정
fetch.min.bytes : 조회시 브로커가 전송할 최소 데이터 크기 (기본 1)
fetch.max.wait.ms : 데이터가 최소 크기가 될 때까지 기다릴 시간 (기본 500)
max.partition.fetch.bytes: 파티션 당 서버가 리턴할 수 있는 최대 크기 (기본 1MB)
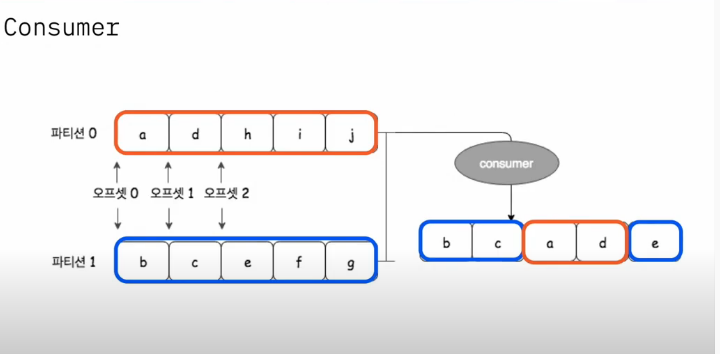
파티션내부에서는 순서를 보장하지만, 다른 파티션과의 순서는 라운드로빈형태다.

기타 카프카 에코시스템
카프카 커넥트
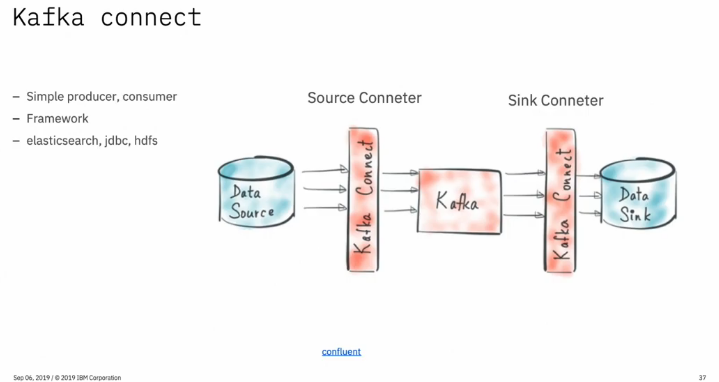
Simple Producer, Consumer.
Producer와 Consumer를 프레임워크 형태로 제공해주는 것.

스키마 레지스트리 - 스키마를 저장하고 이를 통해서 통신할 수 있도록함. (가끔 컨슈머에서 맞지 않는 값때문에 오류가 나는 경우가 있는데 이런 것들을 방지)
기타 디테일한 옵션 부분
log.retention.hours - 어느정도 기간을 보관할 것인지
실제로 diskfull이 일어나는 경우가 많은데, 기본 옵션이 1주일이므로, 생각보다 크게 잡힌다.
delete.topic.enable - 토픽삭제 가능 옵션. diskfull이나면 삭제할 수 있도록.
allow.auto.create.topics - 자동 토픽 생성 옵션.
log.dirs - 초기 옵션은 Temp 폴더에 저장되도록 되어 있는데, Temp는 실제로 임시 저장소의 의미로 OS에 의해서 예기치 않게 삭제될 수 있다.
min.insync.replicas - 프로듀서 ack옵션이 all일 때 저장된 replica의 개수.
'Developer > Web' 카테고리의 다른 글
| Node.js + js 를 쓰면서 불편했던 점, Nestjs+Typescript의 이점 (0) | 2022.02.06 |
|---|---|
| GraphQL은 REST API와 무엇이 다를까? (Node.js + Apollo 예시) (0) | 2021.02.07 |
| CI? CD? Cloud Native? DevOps? 헷갈리는 용어 정리하기 (0) | 2021.01.27 |
| Node.js는 Apache, 톰캣과 같은 개념과 무엇이 다른가? (0) | 2020.11.04 |
